无极限飙车2无限金币版是款畅爽赛车模拟游戏,涵盖跑车、超级跑车等车型,每款均有独特性能。玩家可调车设以提升性能,并熟练掌握驾驶技巧以获赛道优势。支持多人联机对战,与全球玩家竞速,感受真实赛车竞技氛围,享受高速与激情。
1、游戏提供多样化的难度和内容,每个难度和内容都对应着不同的奖励和竞争对手。
2、玩家在成功击败对手后,将赢取丰厚的奖励,并沉浸在逼真的物理设定和精美的画面制作中。
3、细腻逼真的游戏画面,带给你身临其境的摩托车驾驶体验,同类型的游戏却带来别样的感觉。
4、通过积累的经验值,你可以升级角色,解锁更多赛车和更吸引人的游戏玩法。
5、要解锁更多赛道,你需要考取更高级别的摩托车驾照以获取相应的权限。
1、弯道撞翻
游戏中弯道撞翻相对有技巧性。在拐弯的时候你直接瞄准对手直冲过去就可以将对手轻松撞翻(当然要准点),方向在撞翻之后会被系统自动修复,所以你不用担心撞毁的问题。不过,这样有一定的风险,因为一旦没有撞翻对手,就很可能自己撞毁。因此有一个折中的方案出现了。也就是在拐弯的时候漂移,用车的侧面撞击对手,这样可以使对手拐弯不灵而撞毁,不过这样做成功的几率相对较低。

2、直道撞翻
要在直道中撞翻对手,从后面撞翻几乎是不可能的(除非对手前面有障碍)。所以,我们要在侧面寻求机会。在位于对手斜后方时,也尽量不要觉得他装甲薄就去强行撞击,因为很可能你刚一转头电脑一把加速就跑了,反倒让你撞到墙上。而在对手侧面时,就可以直接拐弯来把它憋死在墙上。而你在他斜前方时,你可以通过漂移斜在他前面(注意不要横过来,不要撞毁在墙上),这样会把它挤翻。双方都在道路中间时,如果速度比较快,你可以在处于他前方时进行漂移甩尾,让他自己由于车体难以克服的惯性一头撞在墙上(这样也算你撞翻的),同理,你也可以挤他,使他撞在路上的障碍物上面。这样的好处是不会明显的减速(因为摩擦的时间短,且相对速度小)。当然,这么做之前建议你把装甲升级一下(不必升太多,两三级足够)。
3、淘汰赛
淘汰赛的打法基本和竞速一样,但是有一点要注意,前期你积累氮气倒是可以,不过要小心被淘汰。因此我推荐你时刻都撞一辆对手给你当垫背。到后期也不用一直领先,如果有对手紧跟在你后面,就不用氮气,留一把极速把它撞翻,这样不出意外他就没法超过你了,你就可以一直保持不落后于第一名了。如果你不留氮气,的确可以在速度上领先一点,但由于你们差距不大,损毁时由于现加速太慢很有可能被淘汰。如果通过撞击确定优势则可以拉对手很远,这样即使损毁也还有追回来的机会。
4、租车
经验表示,租车不是一个好的方式,因为租来你也不能升级,不能升级的车和原本自己升级了的车是没有多大区别的。就算租来的很强力,上道了你也不 能保证不失误,失误了还不是第一,结果租金已经付过了。认为在7个等级上,一旦解锁了每个等级最新的车,就立马买了,然后升级。不要觉得钱不够,从头玩到尾,从来也没缺过钱。再有,一定要给你的爱车喷上自己喜欢的外表,别以为这没什么,其实这会影响你的心情。设想一下,开着自己设计外观的车跟别人比赛,首先在气势上,斗志上,心里上就赢了

5、漂移
狂飙里的漂移很简单,按下刹车然后转向就会自动漂移,控制好力度和方向就行。需要主要的是很多时候要及时取消漂移,否则会撞的很惨。取消漂移的办法就是再按下刹车或者直接开氮气。
6、换气
换气的概念很简单,就是保证氮气槽有足够喷出三级气的氮气余量,那么怎么达到每次喷气都是三级这个目标呢,还是换气。氮气量在氮气槽的中间微微靠左边一点点,就是喷出三级气最基本要求,很多人集满了气之后就极速喷气,直到喷完后又再漂移集气,积满了再喷,这个方法很简单,但是很不正确,对于追求速度的人来说,集气的那个缓慢过程中,速度会掉到让人抓狂的程度,等集满了气再喷气加速,这个过程就浪费了很多很多秒,一次又一次的重复这个过程,最后的结果就是你比别人慢上几十秒。那么怎么把这个集气喷气的过程所造成的速度损失减到最小呢,还是换气。
7、通关
(1)很多关卡都不是一次完成的,甚至很多关卡跑完一颗星都没有得到,适应赛道以及玩法和适应你的新女友一样,需要一定的时间,急于求成不是一个好词语。
(2)在一个弯道撞毁了就要重新来过,10次,20次都可以,但如果在一个地方100次撞毁那就可以放弃这个游戏了。
(3)你要知道,电脑是不会抄近路的,也不要以为抄近路不讲究,你跟电脑讲究个什么劲!同时也要知道,不是所有的近路都很近,熟悉地图才是王道。
(4)极速模式是一个神奇的模式,要慎用,更要会用,这个后文会提到。
(5)漂移也不见得是一个神技,不要遇到弯就漂移,也不是所有的直角弯不漂移就过不去。
(6)善用赞助商,你会发现通关其实很简单。
8、物品的收集
游戏当中撞击到一些道具会获得一些名声和美元纸币,可以用来租借车辆或者购买其他改装车辆的物品,所以考验你的技巧的时候就是是否能够及时的在道具出现时切到正确的车道上面拾取他们。
9、平民版满星
(1)很多关卡都不是一次完成的,甚至很多关卡跑完一颗星都没有得到,适应赛道以及玩法和适应你的新女友一样,需要一定的时间,急于求成不是一个好词语。
(2)在一个弯道撞毁了就要重新来过,10次,20次都可以,但如果在一个地方100次撞毁那就可以放弃这个游戏了。
(3)你要知道,电脑是不会抄近路的,也不要以为抄近路不讲究,你跟电脑讲究个什么劲!同时也要知道,不是所有的近路都很近,熟悉地图才是王道。
(4)极速模式是一个神奇的模式,要慎用,更要会用,这个后文会提到。
(5)漂移也不见得是一个神技,不要遇到弯就漂移,也不是所有的直角弯不漂移就过不去。
(6)善用赞助商,你会发现通关其实很简单。
1、游戏提供了四种操控赛车的方式:
(1)倾斜设备转向+自动加速
(2)倾斜设备转向+手动加速
(3)屏幕滑动转向+自动加速
(4)屏幕点击转向+自动加速
2、倾斜转向操控方式
在手机旋转屏幕+自动加速的方式最易操控,也是大多数玩家采用的。在倾斜屏幕方式中下,
(1)加速:触击屏幕右下(触击时出现氮气标记)
(2)刹车:触击屏幕左下(触击时出现刹车标记)
(3)转向:旋转屏幕,设备向左倾斜为向左转,反之为向右转
3、玩家视角
游戏提供了四种视角:固定视角、靠近视角、拟真视角和动作视角。不同的视角给玩家带来的体验是不同的,玩家可以选择自己习惯的视角。
4、腾空
又称“飞跃”,指车体跃离地面并在空中有一定时间的滞留。游戏中的腾空有向前腾跃、水平螺旋和桶滚三种。游戏中有很多坡道可以腾空,腾空可以产生氮气,但同时也降低了行进速度。
(1)向前腾跃
即以一定前行速度从高处落下,此时玩家并不需要特别的操作,但要注意速度和空中转向。在有些场景,落地点较远或者落地点附近有障碍物,玩家必须在腾跃前保持一定的速度才能通过。
水平螺旋和桶滚详见后文。
1、首先大家进入无极限飙车2游戏,由于刚进入游戏没有赛车可以挑战,所以我们先要点击左下角的商店进行购买;
2、在这里大家可以购买自己喜欢的赛车,在足够的金币下哦!
3、购买完之后,如果在颜色上还是不太满意,或者其他地方不太喜欢,我们还可以进行改装,点击首页的下方第四个按钮可以进行改装;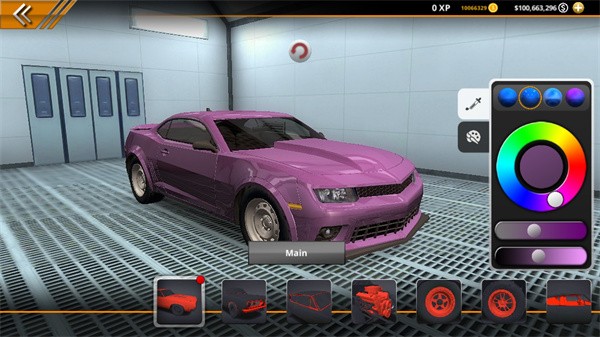
4、改装玩之后开始进入游戏,在图下选择一个街道进入;
5、进入之后还要选择一个地图进行挑战,选择完点击race;
6、开始挑战之后,我们要比别人先过终点才能获得奖励。